Bir önceki yazımda Apache Spark kurlumunu ve basit bir kaç örneği incelemiştik. Bu yazıda RDD("resilient distributed dataset) yani esnek dağıtık veri kümelerini inceliyor olacağız.
RDD'ler basitçe değişmez(immutable) dağıtık obje koleksiyonlarıdır ve her biri farklı düğümlerde hesaplanmak üzere çeşitli parçalara bölünmüş şekildedir. Python, Scala veya Java'nın sahip olduğu tüm obje türlerini içerebilmekle beraber sizin de tanımladığınız sınıfları içerebilir.
Önceki yazımda; örneğimizde lines = sc.textFile("README.md") gibi bir kod kullandık. Bu kullanım ile aslında Python'da bir string RDD'si yaratmış olduk.
Oluşturulan bir RDD yaratıldıktan sonra iki çeşit operasyonla kullanılabilir(bkz:transformations veya actions). Transformation işlemleri ile bir önceki RDD'den yeni bir RDD yaratılmasını sağlar.Örneğin bir önceki yazıda kullandığımız örneğe bakalım.
pythonLines = lines.filter(lambda line: "Python" in line)
Burada bir önceki RDD'yi('lines') kullanarak yeni bir RDD('pythonLines') oluşturuyoruz.
Action ise sahip olduğumuz RDD üzerinde hesaplama türü işlemler yapmaktır. Örneğin;
pythonLines.first()
Cache veya Persist
Eğer elinizdeki bir RDD'yi birçok kez kullanacaksak ve performansdan kazanmak istiyorsak, Spark'a bunu RDD.persist() şeklinde bildirerek, memory'i kullanarak daha fazla performans elde edebilirsiniz(cache(), persist() ile aynı işlevi görür).Yazının devamında bu konuyu işliyor olacağız fakat kullanımı aşağıdaki gibidir.
pythonLines.persist
Özetlemek gerekirse her Spark uygulaması aşağıdaki gibi bir yol izler.
- Elindeki verilerden RDD'ler oluştur.
- Yeni RDD'ler elde et.(Transformation aşaması)
- Eğer birden fazla işlem yapacaksan Spark'a persist işlemini bildir.
- Elindeki veriyi işle.(Action aşaması)
RDD oluşturmak
1.Var olan bir koleksiyondan
lines = sc.parallelize(["burak", "kose", "arch" , "linux"])
Protatip ve test işlemleri yaparken uygun olan bir yöntemdir fakat gerçek zamanlı uyglamalarda çok da kullanışlı değildir, çünkü tek bir makinenin hafızasında büyük bir veri olması gerekmektedir ve dolayısı ile çoğu zaman böyle bir kaynak mümkün değildir.
2.Harici depolamadan
data = sc.textFile("file-path") şeklinde kullanımdır.
Dönüşümler(Transformations)
Yürütülen her bir transformation işlemi gerçekten bir action ile karşılaşana kadar gerçekleştirilmez.Buna "Lazy Evaluation" denir. "Lazy Evaluation" terimine daha önce foksiyonel bir programlama dili uğraşanlar aşinadır fakat terimi kısaca açıklamak gerekirse bir işlemin mecbur kalınana kadar yürütülmediği bir yaklaşımdır.
Bir örnek gösterelim, elimizde bir log dosyası olsun ve biz içerisinde "error" geçen logları elde etmek isteyelim.Yapmamız gereken
Örnek : filter()
input = sc.textFile("log.txt")
error = input.filter(lambda x: "error" in x)
şeklinde olacaktır.error'un yeni bir RDD olduğuna dikkat edin.
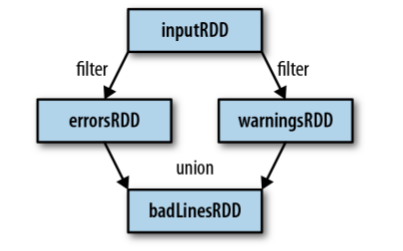
Örnek : union()
errorsRDD = inputRDD.filter(lambda x: "error" in x)
warningsRDD = inputRDD.filter(lambda x: "warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
Yapılan işleri aşağıdaki gibi bir görsel ile özetleyebiliriz.
İki çok genel transformation işlemi vardır, map ve filter. Bunların işlevleri aşağıdaki görseldeki gibi açıklanabilir.
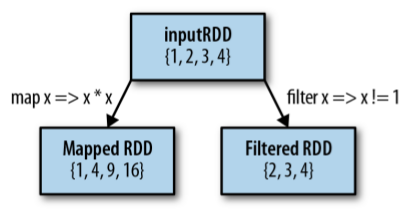
Örnek : map()
>>> nums = sc.parallelize([1, 2, 3, 4])
>>> squared = nums.map(lambda x: x * x).collect()
>>> squared
[1, 4, 9, 16]
gibi verilen parametredeki sayıların karesini alan bir örnek yazabiliriz.
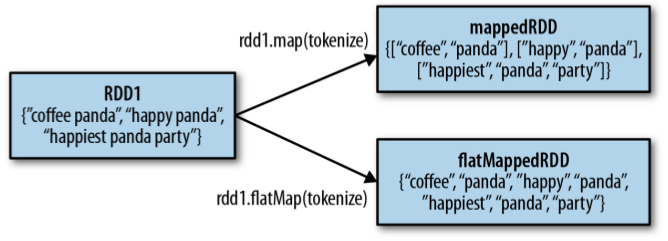
Bazen map işleminin tersine her bir giriş ifadesine karşın birden fazla çıktı üretmek isteriz.Bu tip durumlarda kullanılan operasyon flatMap()'dir. Aşağıdaki örnek girdi olarak verilen metni basitçe kelimelerine ayırır.
Örnek : flatMap()
>>> lines = sc.parallelize(["hello world", "hi"])
>>> words = lines.flatMap(lambda line: line.split(" "))
>>> words.first()
'hello'
Aşağıdaki görselde aynı işlemin map ve flatMap arasındaki farkı özetlenmektedir.
Transformation işlemlerini incelemeye devam edelim.
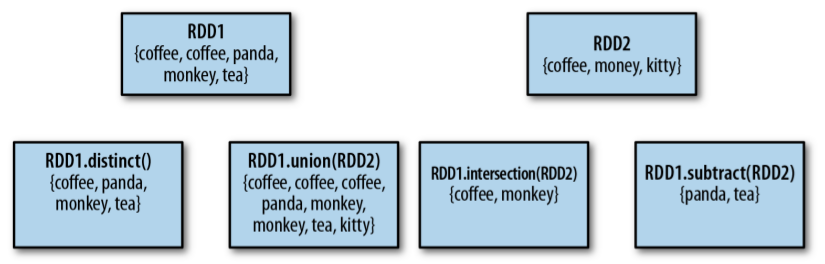
Yukarıdaki görseli açıklamak istersek kısaca, - distinct işlemi ile tekrar eden kayıtları atarak geriye eşsiz kayıtlardan oluşan bir RDD elde edebiliriz. - union işlemine daha önce değinmiştik.İki RDD'yi birleştirme işlevini görür fakat elemanların tekrarı ile ilgilenmediğine dikkat edin. - intersection işlemi iki RDD arasındaki ortak elemanları elde etmemizi sağlar. - subtract ile fonksiyona parametre olarak verilen RDD'deki elemamanlar dışındaki verileri elde ederiz.
Bunların dışında iki RDD arasında kartezyen çarpım da elde edebiliriz. Bunun için RDD1.cartesian(RDD2) uygulamamız yeterlidir.
Eylemler(Actions)
RDD oluşturmayı, var olan bir RDD'den yeni bir RDD yaratmayı transformation bölümünde gördük.Şimdi sıra veriler ile oynamada. Yapacağımız şey yukarıdaki örnekte elde ettiğimiz badLinesRDD içerisindeki '5' log satırını görüntülemek olsun.
Örnek : take()
print(badLinesRDD.count()," lines")
print("İşte beş örnek")
for line in badLinesRDD.take(5):
print(line)
take() gibi birde collect() vardır fakat collect() kullanacaksanız veri boyutunun çok küçük olması gerektiği ve tek bir makinede çalışmanız gerektiğini unutmayın. Dolayısı ile collect() büyük veri kümelerinde çalışmak için uygun değildir.
Sanırım en çok kullanılan action reduce'dur. Kullanımı aşağıdaki gibidir.
sum = rdd.reduce(lambda x, y: x + y)
veya Python'da operator modülünü kullanabiliriz.
from operator import add
sum = rdd.reduce(add)
Dikkat ettiyseniz reduce fonksiyonu geriye içinde işlem yaptığımız RDD'nin sahip olduğu tipte bir değer döndürmektedir.Bu yukarıdaki gibi toplama işlemi gibi operasyonlar da başarılı fakat geriye tek bir değer değil bir ikili döndürmek isteyebiliriz.
Diğer basit action işlemlerini inceleyelim. İleride daha ayrıntılı bir biçimde tüm action işlemlerini inceleyeceğiz.
| Fonksiyon | Açıklaması | Kullanım | Sonuç |
|---|---|---|---|
| collect() | RDD'deki tüm elemanları döndürür | rdd.collect() | [1, 2, 3, 3] |
| count() | RDD'deki eleman sayılarını döndürür | rdd.count() | 4 |
| countByValue() | RDD içerisindeki her bir elemanın kaç defa geçtiğini bilgisini verir | rdd.countByValue() | [(1, 1),(2, 1),(3, 2)] |
| take(num) | RDD'den num sayısı kadar eleman döndürür | rdd.take(2) | [1, 2] |
| top(num, key=None) | RDD'den en büyük num sayısı kadar sayı döndürür | rdd.top(2) | [3, 3] |
| takeOrdered(num, key=None) | Parametlere olarak verilen sıralama şartına göre num adet sıralanmış örnek döndürür | rdd.takeOrdered(2) | [3, 3] |
| takeSample(withReplacement, num, [seed]) | Rastgele n eleman döndürür | rdd.takeSample(True, 1, 1) | Kestirilemez |
| reduce(func) | Paralel olarak elemanları birleştirir | rdd.reduce(lambda x,y:x+y) | 9 |
| foreach(func) | Parametre olarak verilen fonksiyon tün elemanlar üzerinde uygulanır | rdd.foreach(func) |
Önbellekleme(Caching)
Spark RDD'lerinin "lazily evaluated" olduğundan bahsetmiştik. Bazen uygulamalarımızda bir RDD'yi birden fazla kez kullanmamız gerekebilir. Eğer bunu doğrudan yapıyor olsaydık, bizim her action isteğimizde, Spark bu RDD'yi ve bağımlılıklarını tekrar tekrar hesaplamak zorunda kalacaktı. Dolayısıyla iteratif algoritmaları kullanmamız gerektiğinde çok masraflı olacaktır. Bu konunun önemi çok fazladır, yazdığınız bir uygulama sorunsuz çalışıyor gibi gözükebilir fakat anlam veremediğiniz bir şekilde yavaş çalışıyorsa ilk olarak önbellekme konusunu incelemenizi tavsiye ederim. Bir örnek yapalım ve ne demek istediğimize bakalım.
Örnek : Çift hesaplamalı
from operator import add
from pyspark import SparkContext
if __name__ == '__main__':
sc = SparkContext(appName='myname')
data = sc.parallelize(range(10)) \
.map(lambda x: x ** 2)
print(data.count())
print(','.join(str(s) for s in data.collect()))
Bu tip bir performans kaybı yerine, Spark'a bu datayı 'persist' edebilir misin diye sorarız.
Birden fazla seviye vardır.Genel olarak aşağıdaki gibi açıklanabilir.
| Seviye | Yer kullanımı | CPU kullanımı | Bellekte mi? | Diskte mi? | Açıklama |
|---|---|---|---|---|---|
| MEMORY_ONLY | Yüksek | Düşük | Evet | Hayır | |
| MEMORY_ONLY_SER | Düşük | Yüksek | Evet | Hayır | |
| MEMORY_AND_DISK | Yüksek | Orta | Birazı | Birazı | Veri bellek için fazla büyükse veri parçalarını diske koymaya başlar |
| MEMORY_AND_DISK_SER | Düşük | Yüksek | Birazı | Birazı | Veri bellek için fazla büyükse veri parçalarını diske koymaya başlar. Serilize edilerek saklanır |
| DISK_ONLY | Düşük | Yüksek | Hayır | Evet |
Örnek : Persist kullanımı
from operator import add
from pyspark import SparkContext
if __name__ == '__main__':
sc = SparkContext(appName='myname')
data = sc.parallelize(range(10)) \
.map(lambda x: x ** 2)
data.persist(StorageLevel.DISK_ONLY)
print(data.count())
print(','.join(str(s) for s in data.collect()))
Not:persist() fonksiyonunun RDD henüz action ile karşılaşmadan önce çağrıldığına dikkat edin.
Eğer belleğe sığamayacak kadar veriyi önbelleklemeye çalışırsanız Spark otomatik olarak kendini Least Recently Used (LRU) politikasına göre düzenleyecektir.
Burada bahsedilenden çok daha fazla sayıda transformation ve action işlemi vardır. Çok daha ayrıntılı biçimde ileriki yazılarımda bahsedeceğim.
BURAK KÖSE
Comments
comments powered by Disqus