Apache Spark,büyük veri işleme amacı ile oluşturulmuş bir Apache projesidir.Scala dili ile yazılmış JVM üzerinde çalışan ve Python, Java, Scala kullanımına olanak sağlayan, "in-memory" yani veriyi bellek içerisinde işleme özelliği ile ön plana çıkan bir projedir.
Eğer isterseniz kaynak kodları görüntülemek için aşağıdaki adrese göz atabilirsiniz.
https://github.com/apache/spark
Kurulum
http://spark.apache.org/downloads.html adresinden “Pre-built for Hadoop 2.6 and later” seçeneği seçilerek son sürümünü indirebilirsiniz.İndirme tamamlandıktan sonra indirilen yere geçirelerek,
tar -xzvf spark-1.4.0-bin-hadoop2.6.tgz
cd spark-1.4.0-bin-hadoop2.6
ls
komutları yürütülür.Son komuttan sonra sergilenen dosyaları kısaca şu şekilde açıklayabiliriz.
- README.md
Spark ile ilgili kısa açıklamalar ve hızlı başlangıç
- bin
Çalıştırılabilir dosyalar(shell gibi)
- core,streaming,Python..
Spark projesinin kaynak kodları
- examples
Örnekler
Tanıtım
Yazının devamında Spark'ı yerel modda çalıştırarak kısa bir kaç örnek yapalım.Ben Python kullanıyor olacağım eğer siz tercih ederseniz Scala veya Java kullanabilirsiniz fakat Java hakkında bahsetmek istediğim bir nokta var eğer Java 8 ile birlikte gelen özellikleri kullanmazsanız nispeten biraz okuması zor bir kod çıkabilir ortaya fakat performanstan bir kaybınız olmaz.
- İnteraktif Python Shell
./bin/pyspark
- İnteraktif Scala Shell
./bin/spark-shell
Python shell için yukarıdaki komutu çalıştırdıktan sonra şu şekilde bir görüntü elde ediyorum.
Eğer konsola düşen "INFO" loglarını gizlemek isterseniz.Şunu yapabilirsiniz.
"conf/log4j.properties.template"
dosyasının bir kopyasını alın ve
"conf/log4j.properties"
ismini verin.Daha sonra bu kopya dosya içerisindeki "log4j.rootCategory=INFO, console" satırını "log4j.rootCategory=WARN, console" ile değiştirin.Artık INFO loglarını görmeyeceksiniz.
Devam edelim,interaktif Python Shell açtıktan sonra
>>> lines = sc.textFile("README.md")
>>> type(lines)
<class 'pyspark.rdd.RDD'>
>>> lines.count()
98
>>> lines.first()
'# Apache Spark'
gibi bir örnek ile test edelim.Yukarıdada göreceğiniz gibi lines adı ile kullandığımız değişkten bir RDD objesidir ve yerel makinemizde bulunan bir text dosyasından oluşturulmuştur.RDD hakkında ileriki yazılarımda daha fazla detay vereceğim.
Yukarıdaki örnekte birde sc objesi kullandık.Bu obje sayesinde Spark ile iletişim kurulur.
>>> sc
<pyspark.context.SparkContext object at 0x7f9b3e856e48>
Spark aşağıdaki görseldeki gibi çalışır.
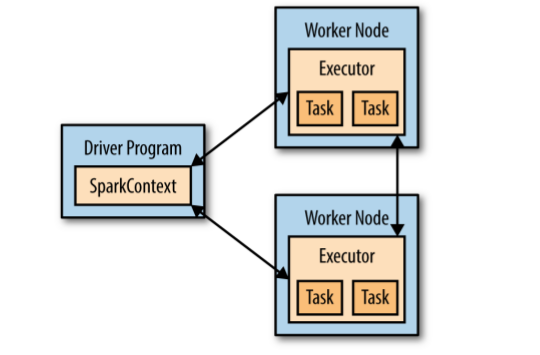
Şimdi de bu uygulamamızda filter kullanarak içerisinde "Python" geçen satırları veren bir örnek yapalım.
>>> lines = sc.textFile("README.md")
>>> pythonLines = lines.filter(lambda line : 'Python' in line)
>>> type(pythonLines)
<class 'pyspark.rdd.PipelinedRDD'>
>>> pythonLines.count()
3
>>> pythonLines.first()
'high-level APIs in Scala, Java, and Python, and an optimized engine that'
Gibi bir çıktı alırız.Eğer Python'da lambda fonksiyonlara alışık değilseniz ya da kullanmak istemezseniz yukarıda kullandığımız filter() methoduna kendi oluşturduğunuz methodu da aktarabilirsiniz.Örnek;
>>> def hasPython(line):
... return 'Python' in line
...
>>> pythonLines = lines.filter(hasPython)
gibi bir kullanım geçerleyebilirsiniz.
İnteraktif shell kullanışlı olsa da her zaman kullanamayız.Bazen bağımsız uygulamalar yazmamız gerekmektedir.Yazılan kodları yürütmek için indirdiğimiz Spark klasöründeyken ./bin/pyspark benim_script.py komutunu yürütmek zorundayız.Bunun yerine aşağıdaki yolları izleyerek işimizi biraz daha kolaylaştıralım.
cd ~
nano .bashrc
ve aşağıdaki satırları düzenleyip dosyamıza ekleyelim.
export SPARK_HOME= 'Spark dosyası uzantısı'
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH
. .bashrc
PySpark'ın py4j adlı pakete bağımlılığı vardır.Bu paket Python yorumlayıcısının dinamik bir şekilde Spark ile haberleşmesini sağlar.
pip install py4j
Yazdığımız kodları artık
./bin/spark-submit <python_file.py>
yerine direk olarak
python <python_file.py> şeklinde çalıştırabileceğiz.
Bundan sonra kod yazarken yapmamız gereken tek şey SparkContext objemizi oluşturmaktır,geri kalan kısımlar aynıdır.
Yazımın başında Python kullandığımı söylemiştim fakat siz Scala veya Java kullanıyorsanuz bağımsız uygulamalar yazarken Maven kullanmanızı öneririm.Maven kullanımı ile ilgili resmi dökümanlara bakarak yardım alabilirsiniz.
Yazılan uygulamanın Spark ile iletişim kurabilmesi için Spark paketlerini dahil etmeli ve SparkContext nesnesini yaratmalıyız.
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
Yazdığımız script'i
python benim_script.py
şeklinde çalıştırabilirsiniz.
Bu örnek ile basit olarak SparkContext oluşturmayı gördük.Aktarılan iki parametre sırası ile;
- Cluster URL , bu örnekte "local" olmasının sebebi Spark'ı tek bir makinede ve tek bir thread üzerinde çalıştırdığımız içindir.
- Uygulama ismi
Bu parametreler dışında parametreler bulunmaktadır,ileride daha ayrıntılı inceliyor olacağız.
Eğer uygulamayı sonlandırmak isterseniz SparkContext objesi üzerinden stop() methodunu çağırabilir veya alışık olduğumuz sys.exit() kullanabilirsiniz.
Bu kadar kargaşadan sonra sıra "Hello World" uygulamamıza geldi.Bu alanın "Hello World" uygulaması "Word Count" olarak geçer.Basit bir word count uygulaması yazalım.
from operator import add
from pyspark import SparkContext
if __name__ == "__main__":
sc = SparkContext(appName="WordCount")
lines = sc.textFile('README.md')
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
sc.stop()
Kod içerisinde yabancı gelen terimleri bir sonraki yazılarda daha ayrıntılı bir biçimde inceliyor olacağız.
BURAK KÖSE
Comments
comments powered by Disqus